Карысныя спасылкі
Хатняя старонка
Хатняя старонка на Oracle.com: https://www.oracle.com/java/
Даведнікі і кнігі
Даведнік па Java на Oracle.com: http://docs.oracle.com/javase/tutorial/index.html
Шэраг даведнікаў, прысьвечаных розным тэмам вакол Java на tutorialspoint.com: http://www.tutorialspoint.com/java_technology_tutorials.htm
Java: The Complete Reference (дзевятае выданьне папяровай кнігі, аўтарства Herbert Schildt ад выдавецтва Oracle Press, на жаль электроннага варыянту няма ў вольным доступе). Ці перакладзенае на расейскую мову выданьне гэтай кнігі: ozon.ru.
Блогі
Ядро
Тыпы даных
Апэрацыі
Інструкцыі
Клясы
Generics
Выключэньні
Multithreading
I/O
Lambda-выразы
Lambda-выразы – гэта рэалізацыя абстрактнага мэтаду функцыянальнага інтэрфэйсу. Функцыянальны інтэрфэйс – гэта інтэрфэйс, які ўтрымлівае адзін і толькі адзін мэтад. Самымі відавочнымі прыкладамі функцыянальнага інтэрфэйсу зьяўляюцца старыя добрыя інтэрфэйсы кшталту:
java.lang.Runnableз адзіным мэтадамvoid run();- альбо
java.awt.event.ActionListenerз адзіным мэтадамvoid actionPerformed(ActionEvent e).
Любы інтэрфэйс з адзіным мэтадам зьяўляецца функцыянальным, нічога дадаткова рабіць ня трэба, але аўтар такога інтэрфэйсу можа яўна пазначыць свой намер і абмежаваць зьмены ў такім інтэрфэйсе праз анатацыю @FunctionalInterface. У такім выпадку кампілятар ня дасьць дадаць у такі інтэрфэйс дадатковы мэтад, альбо прыбраць існы. Вось як выглядае рэалізацыя інэтрфэйсу Runnable:
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
Адпаведна, калі да 8-ай вэрсіі неабходна было пісаць:
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Hello from thread");
}
}).start();
Пачынаючы з 8-ай вэрсіі, тое ж самае можна зрабіць наступным чынам:
new Thread(() -> System.out.println("Hello from thread")).start();
Як бачым варыянт з лямбда-выразам значна больш ляканічны.
Разгледзім сынтаксіс лямбда-выразу. Спачатку ідзе сьпіс парамэтраў у дужках. Тыпы парамэтраў пазначаць не абавязкова, яны будуць аўтаматычна вызначаныя кампілятарам у залежнасьці ад кантэксту, дзе лямбда-выраз выкарыстоўваецца. Калі парамэтар адзіны, дужкі не абавязковыя:
new JButton().addActionListener(e -> System.out.println(e.getActionCommand()));
Пасьля сьпісу парамэтраў ідзе адмысловая апэрацыя ->, а пасьля яе ідзе цела выразу, а фактычна цела мэтаду інтэрфэйса, які выраз рэалізуе. Калі цела лямбда-выразу складаецца з больш, чым адной інструкцыі, яго трэба абгортваць у фігурныя дужкі:
interface NumericFunc {
int func(int n);
}
class BlockLambdaDemo {
public static void main(final String args[]) {
final NumericFunc factorial = (n) -> {
int result = 1;
for(int i=1; i <= n; i++) result = i * result;
return result;
};
System.out.println("The factoral of 3 is " + factorial.func(3));
System.out.println("The factoral of 5 is " + factorial.func(5));
}
}
Generic функцыянальныя інтэрфэйсы
Лямбда-выразы ня могуць вызначаць тыпы сваіх аргумэнтаў, яны вызначаюцца аўтаматычна ў залежнасьці ад інтэрфэйсаў, якія лямбда-выразы рэалізуюць. Таму лямбда-выразы ня могуць быць generic. Але самі функцыянальныя інтэрфэйсы могуць быць такімі:
// A generic functional interface.
interface SomeFunc {
T func(T t);
}
class GenericFunctionalInterfaceDemo {
public static void main(String args[]) {
// Use a String-based version of SomeFunc.
SomeFunc reverse = (str) -> {
String result = "";
for(int i = str.length()-1; i >= 0; i--) result += str.charAt(i);
return result;
};
System.out.println("Lambda reversed is " + reverse.func("Lambda"));
System.out.println("Expression reversed is " + reverse.func("Expression"));
// Now, use an Integer-based version of SomeFunc.
SomeFunc factorial = (n) -> {
int result = 1;
for(int i=1; i <= n; i++) result = i * result;
return result;
};
System.out.println("The factoral of 3 is " + factorial.func(3));
System.out.println("The factoral of 5 is " + factorial.func(5));
}
}
Прадвызначаныя інтэрфэйсы агульнага прызначэньня
Пакет java.util.function у Java 8 утрымлівае шэраг прадвызначаных функцыянальных інтэрфэйсаў агульнага прызначэньня (унівэрсальных):
| Інтэрфэйс | Прызначэньне |
|---|---|
UnaryOperator<T> |
Ужывае ўнарную апэрацыю да аб'екта тыпу T і вяртае вынік таго ж тыпу. Мэтадам гэтага інтэрфэйсу зьяўляецца мэтад apply(). Рэалізуецца як Function<T, T> |
BinaryOperator<T> |
Ужывае бінарную апэрацыю да 2 аб'ектаў тыпу T і вяртае вынік таго ж тыпу. Мэтад apply(). Рэалізуецца як BiFunction<T, T, T> |
DoubleBinaryOperator |
Ужывае бінарную апэрацыю да 2 аб'ектаў тыпу double і вяртае вынік таго ж тыпу. Мэтад applyAsDouble(). |
Consumer<T> |
Ужывае апэрацыю да аб'екта тыпу T. Мэтад accept(). Усе consumer-апэрацыі ў адрозьненьні ад іншых маюць пабочны эфэкт. |
BiConsumer<T, U> |
Ужывае апэрацыю да двух сваіх аргумэнтаў, адзін тыпу T, іншы тыпу U. Мэтад accept() |
Supplier<T> |
Вяртае аб'ект тыпу T. Мэтад get() |
BooleanSupplier |
Вяртае значэньне тыпу boolean. Мэтад getAsBoolean() |
Function<T, R> |
Ужывае апэрацыю да аб'екта тыпу T і вяртае аб'ект тыпу R у якасьці выніку. Мэтад apply() |
BiFunction<T, U, R> |
Ужывае апэрацыю да аб'ектаў тыпу T і тыпу U, потым вяртае аб'ект тыпу R у якасьці выніку. Мэтад apply() |
Predicate<T> |
Вызначае ці адпавядае аб'ект тыпу T пэўным умовам, аб чым кажа значэньне тыпу boolean, якое вяртае ягоны мэтад test() |
BiPredicate<T> |
Вызначае ці адпавядаюць аб'екты тыпу T і тыпу U пэўным умовам, аб чым кажа значэньне тыпу boolean, якое вяртае ягоны мэтад test() |
| Дарабіць, ня ўсе інтэрфэйсы пералічаны |
Большасьць з гэтых інтэрфэйсаў рэалізуюць змоўчны мэтад andThen() для магчымасьці спалучаць пасьлядоўныя выклікі ў ланцуг.
Спасылкі на мэтады
Спасылкі на мэтады дазваляюць, аднойчы вызначыўшы пэўны мэтад, перадаваць яго як лямбда-выраз. Уявім у нас ёсьць наступны код, напісаны пры дапамозе звычайнага лямбда-выразу (рэалізацыя мэтаду boolean accept(File pathname) функцыянальнага інтэрфэйсу java.io.FileFilter):
File[] hiddenFiles = mainDirectory.listFiles(f -> f.isHidden());
Тое ж самае можна напісаць яшчэ больш ляканічна і выразна, а галоўнае без неабходнасьці кожны раз вызначаць адзін і той жа лямбда-выраз у шматлікіх месцах, пры дапамозе спасылкі на мэтад:
File[] hiddenFiles = file.listFiles(File::isHidden);
Існуе 4 асноўных тыпаў спасылак на мэтады:
-
Спасылка на статычны мэтад:
// Вызначэньне Function<String, Integer> кажа аб тым, што гэта функцыя, // якая прымае String у якасьці адзінага парамэтру і вяртае Integer. // apply - мэтад які запускае функцыю на выкананьне. Function<String, Integer> converter = Integer::parseInt; Integer number = converter.apply("10"); -
Спасылка на мэтад экзэмпляру клясы:
Function<Invoice, Integer> invoiceToId = Invoice::getId; -
Спасылка на мэтад пэўнага экзэмпляру клясы:
Асабліва карысны гэты тып для выпадкаў, калі вы жадаеце зрабіць іньекцыю прыватнага дапаможнага мэтаду ў іншае месца праграмы:Consumer<Object> print = System.out::println;... File[] hidden = mainDirectory.listFiles(this::isXML); ... private boolean isXML(File f) { return f.getName.endsWith(".xml"); } -
Спасылка на канструктар:
Supplier<List<String>> listOfString = List::new;
Выніковы прыклад
Напрыканцы разгледзім паступовую пераробку аднаго прыкладу з цалкам Java 7 варыянту ў цалкам Java 8 варыянт. Уявім, што ў нас ёсьць наступны код упарадкаваньня сьпісу інвойсаў па іх велічыні:
Collections.sort(invoices, new Comparator() {
public int compare(Invoice inv1, Invoice inv2) {
return Double.compare(inv2.getAmount(), inv1.getAmount());
}
});
Па-першае Comparator зьяўляецца функцыянальным інтэрфэйсам, адзіны мэтад якога прымае 2 аргумэнты аднаго тыпу і вяртае цэлалікавае значэньне, і ідэальна падыходзіць для замены ананімнай яго рэалізацыі лямбда-выразам:
Collections.sort(invoices,
(Invoice inv1, Invoice inv2) -> return Double.compare(inv2.getAmount(), inv1.getAmount()));
Далей, у Java 8 мэтад упарадкаваньня быў уведзены ў сам сьпіс, таму няма неабходнасьці ўжываць дапаможны мэтад Collections.sort:
invoices.sort((Invoice inv1, Invoice inv2) -> return Double.compare(inv2.getAmount(), inv1.getAmount()));
Наступны крок. У Java 8 маецца дапаможны мэтад Comparator.comparing, які ў якасьці аргумэнту прымае лямбда-выраз для атрыманьня ключа, па якому будзе рабіцца ўпарадкаваньне, і сам створыць адпаведны аб'ект Comparator:
invoices.sort(Comparator.comparing(inv -> inv.getAmount()));
Наступным крокам можна лямбда-выраз у апошнім прыкладзе замяніць на спасылку на мэтад:
invoices.sort(Comparator.comparing(Invoice::getAmount));
Як бачым, апошні варыянт нашмат больш ляканічны і выразны.
Бібліятэка
Апрацоўка сымбальных чародаў
Матэматычныя вылічэньні
Рознае ў java.lang
Значэньні даты і часу
Date and Time API у Java 8 падвергнулася значным зьменам. Па-першае, аб'екты даты і часу сталі immutable, што вельмі важна для пазьбяганьня памылак. Па-другое, API стаў значна больш domain driven і інтуітыўна зразумелым:
LocatedDateTime coffeeBreak = LocalDateTime.now().plusHours(2).plusMinutes(30);
Разгледзім комплексны прыклад для ілюстрацыі магчымасьцяў:
ZoneId london = ZoneId.of("Europe/London");
LocalDate may1 = LocalDate.of(2016, Month.MAY, 1);
LocalTime early = LocalTime.parse("08:45");
ZonedDateTime departure = ZonedDateTime.of(may1, early, london);
System.out.println(departure);
LocalTime from = LocalTime.from(departure);
System.out.println(from);
ZonedDateTime landing = ZonedDateTime.of(may1, LocalTime.of(11, 35), ZoneId.of("Europe/Stockholm"));
Duration flightLength = Duration.between(departure, landing);
System.out.println(flightLength);
ZonedDateTime now = ZonedDateTime.now();
Duration timeHere = Duration.between(landing, now);
System.out.println(timeHere);
Гэты код прывядзе да падобнага вываду:
2016-05-01T08:45+03:00[Europe/Minsk]
08:45
PT3H50M
PT655H49M49.245S
Калекцыі
Streaming API
Streaming API – гэта яшчэ адзін (у дадатак да лямбда-выразаў) зрух у Java 8 у бок дэкляратыўнага, а не імпэратыўнага праграмаваньня, калі мы пазначаем пажаданы вынік замест рэалізацыі кожнай дробнай дэталі дасягненьня гэтага выніку. Напрыклад, мы кажам мове, што мы жадаем атрымаць адсартаваны ці адфільтраваны сьпіс элемэнтаў, пазначаючы толькі пэўныя парамэтры таго, якім чынам яны павінныя быць адсартаваныя і адфільтраваныя, а ўжо якім чынам іх адсартаваць і адфільтраваць, будзе заклапочана сама мова, прычым яно зробіць гэта аптымізаваным чынам.
Streaming API прызначаны палепшыць працу з калекцыямі элемэнтаў. Плынь (stream) у Java 8 – гэта пасьлядоўнасьць пэўных элемэнтаў, прычым плынь не захоўвае самі элемэнты, але мае спасылку на іх крыніцу і перабірае элемэнтамі ў ходзе выкананьня праграмы. Шмат якія апэрацыі плыняў зроблены такім чынам, што яны ізноў вяртаюць плынь з ужо іншымі характарыстыкамі. Гэта зроблена, каб іх можна было злучаць у ланцуг выклікаў – у так званую трубу:
List ids = invoices.stream()
.filter(inv -> inv.getCustomer() == Customer.ORACLE)
.sorted(comparingDouble(Invoice::getAmount))
.map(Invoice::getId)
.collect(Collectors.toList());
Усе апэрацыі, якія падтрымлівае інтэрфэйс java.util.stream.Stream падзяляюцца на 2 катэгорыі:
- такія апэрацыі, як
filter,sortedіmap, якія могуць злучацца ў ланцуг (трубу). - а таксама апэрацыі, як
collect,findFirstіallMatch, якія перарываюць ланцуг выклікаў і вяртаюць вынік.
Фільтрацыя
У Streaming API існуе шэраг апэрацыяў для фільтрацыі элемэнтаў, некаторыя зь іх:
| Апэрацыя | Значэньне |
|---|---|
filter |
Прымае ў якасьці аргумэнту аб'ект Predicate і вяртае плынь, якая будзе ўтрымліваць толькі тыя элемэнты, якія задавальняюць умовам гэтага аб'екту. |
distinct |
Вяртае плынь, якая будзе ўтрымліваць унікальныя элемэнты, у адпаведнасьці з вынікам працы мэтаду equals аб'ектаў у плыні. |
limit |
Вяртае плынь, памер якой ня болей за пазначанае значэньне. |
skip |
Вяртае плынь, выключаючы першыя n-элемэнтаў зыходнай плыні. |
List expensiveInvoices = invoices.stream()
.distinct()
.filter(inv -> inv.getAmount() > 10000)
.limit(5)
.collect(Collectors.toList());
Праверка на адпаведнасьць
Можна праверыць ці адпавядаюць усе/пэўныя/ніякія элемэнты плыні пэўнаму крытэру. Для гэтага ў Streaming API існуюць апэрацыі allMatch, anyMatch і noneMatch. У якасьці парамэтру яны прымаюць Predicate, а вяртаюць вынік тыпу boolean. Прыклад праверкі ці ўсе чэкі маюць суму большую за 1000:
boolean expensive = invoices.stream()
.allMatch(inv -> inv.getAmount() > 1000);
Адзін з мноства
Калі трэба атрымаць проста любы ці першы элемэнт з плыні, можна скарыстацца апэрацыямі findAny і findFirst. У выніку будзе вернуты аб'ект Optional:
Optional = invoices.stream()
.filter(inv -> inv.getCustomer() == Customer.ORACLE)
.findAny();
Mapping
Пры дапамозе мэтаду map можна пераўтварыць кожны элемэнт плыні ў іншы аб'ект. Мэтад прымае ў якасьці аргумэнту аб'ект Function, які пасьлядоўна ўжываецца да кожнага з элемэнтаў плыні, а вынік яго выкананьня фармуе новую плынь. Напрыклад, такім чынам можна атрымаць ID усіх чэкаў, якія ўтрымліваюцца ў зыходнай плыні:
List ids = invoices.stream()
.map(Invoice::getId)
.collect(Collectors.toList());
Reducing
Яшчэ адна апэрацыя, якую часта трэба выканаць над шэрагам элемэнтаў – гэта аб'яднаць нейкім чынам гэтыя элемэнты, каб атрымаць у выніку адно значэньне. Напрыклад, вылічыць суму ўсіх чэкаў у плыні. Клясычна мы б вырашалі гэтую задачу наступным чынам:
double sum = 0;
for (Invoice invoice : invoices) {
sum += invoice.getAmount();
}
У Streaming API існуе мэтад reduce, пры дапамозе якога папярэдні фрагмэнт коду можна перапісаць наступным чынам:
double sum = invoices.stream().map(Invoice::getAmount).reduce(0.0, (a, b) -> a + b);
Альбо яшчэ адзін прыклад, як знайсьці максымальнае значэньне ў плыні лічбаў:
int max = numbers.stream().reduce(Integer.MIN_VALUE, Integer::max);
Collectors
Калі мы скончылі апрацоўваць плынь і трэба вярнуць шэраг яе элемэнтаў, выкарыстоўваецца мэтад collect. У якасьці аргумэнту ён прымае аб'ект java.util.stream.Collector, які апісвае якім чынам трэба сабраць і вярнуць элемэнты. Напрыклад, у ранейшых прыкладах мы ўжо выкарыстоўвалі фабрычны мэтад Collectors.toList(), які вяртае аб'ект Collector з інструкцыямі вярнуць просты сьпіс элемэнтаў:
List invoices = invoices.stream().collect(Collectors.toList());
У клясе Collectors існуюць і іншыя падобныя мэтады, напрыклад:
Map> customerToInvoices = invoices.stream()
.collect(Collectors.groupingBy(Invoice::getCustomer));
Іншае ў java.util
Optional
Для спрашчэньня ланцуговых выклікаў у функцыянальным стылі, каб пазьбягаць NullPointerException, была уведзена кляса java.util.Optional. Уявім прыклад:
getEventWithId(10).getLocation().getCity();
Калі getEventWithId(10) верне null, будзе кінутае выключэньне. Нават калі не, тады існуе магчымасьць, што наступны выклік, getLocation(), таксама верне null і зноў будзе кінутае выключэньне. Іншымі словамі, кожны з выклікаў у ланцугу можа вярнуць null і будзе кінутае выключэньне. Каб пазьбегнуць гэтага, можна ўбудаваць код, які будзе «абараняць» ад выключэньняў, напрыклад такім чынам:
public String getCityForEvent(int id) {
Event event = getEventWithId(id);
if (event != null) {
Location location = event.getLocation();
if (location != null) {
return location.getCity();
}
}
return "TBC";
}
Раней такія праверкі трэба было рабіць ледзь не на кожным кроку. Пачынаючы з Java 8 гэта можна рабіць больш ляканічна:
public String getCityForEvent(int id) {
Optional.ofNullable(getEventWithId(id))
.flatMap(this::getLocation)
.map(this::getCity)
.orElse("TBC");
}
I/O і NIO
Апрацоўка падзеяў
Рэгулярныя выразы
Сетка
Паралельныя і асынхронныя вылічэньні
Уключае клясы і інтэрфэйсы з герархіі java.util.concurrent.
TimeUnit – пералічэньне для пераводу адных адзінак часу ў іншыя:
TimeUnit.HOURS.toSeconds(10);
Semaphore – кляса для таго, каб абмяжоўваць колькасьць патокаў, якія могуць паралельна выконвацца:
public static void main(final String... args) {
Runnable limitedCall = new Runnable() {
final Random rand = new Random();
final Semaphore semaphore = new Semaphore(3);
int count = 0;
public void run() {
int time = rand.nextInt(15);
int num = count++;
try {
semaphore.acquire();
System.out.println("Executing " + "long-running action for " + time + " seconds... #" + num);
Thread.sleep(time * 1000);
System.out.println("Done with #" + num + "!");
semaphore.release();
} catch (InterruptedException intEx) {
intEx.printStackTrace();
}
}
};
for (int i=0; i<10; i++)
new Thread(limitedCall).start();
}
Інтэрфэйс Future<T> – гэта трымальнік значэньня тыпу <T>, характэрнай рысай якога зьяўляецца тое, што значэньне ў агульным выпадку не даступнае да нейкага моманту пасьля стварэньня Future.
Інтэрфэйсы Executor і ExecutorService – гэта нешта, што выконвае задачы. Гэтае нешта і будзе патокам, але інтэрфэйсы хаваюць падрабязнасьці таго, якім чынам паток ажыцьцяўляе выкананьне. Патокі спажываюць адносна шмат рэсурсаў, таму мае сэнс паўторна іх выкарыстоўваць, а не выдзяляць аднакроць з наступным выкідваньнем. Інтэрфэйс ExecutorService спрашчае дзяленьне працы паміж патокамі, а таксама забясьпечвае аўтаматычнае паўторнае выкарыстаньне патокаў, што палягчае праграмаваньне і паляпшае прадукцыйнасьць.
final Collection tasks = new ArrayList();
for (int i = 0; i < 100; i++) {
tasks.add(new Task());
}
ExecutorService threadPool = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
try {
Collection> results = threadPool.invokeAll(tasks);
} catch (InterruptedException e) {
e.printStackTrace();
}
public class Task implements Callable {
public String call() throws Exception {
return null;
}
}
У вышэйпрыведзеным прыкладзе, колькі б не было перададзена патокаў для адначасовага выкананьня (100 у прыкладзе), выконвацца будуць толькі столькі, колькі ядраў/працэсараў у кампутары, на якім прыклад выконваецца, астатнія будуць чакаць сваёй чаргі. Такі падыход адназначна не прывядзе да празьмернай нагрузкі на сыстэму.
Java 8: Definitive guide to CompletableFuture
Java 8 Concurrency Tutorial: Threads and Executors
CompletableFuture
Адной з новых магчымасьцяў Java 8 зьяўляецца кляса java.util.concurrent.CompletableFuture, якая дазваляе рабіць ланцугі выклікаў (камбінаваць некалькі асынхронных выклікаў). У наступным прыкладзе 2 выклікі, якія блякуюць далейшы ход праграмы (атрыманьне цаны і абменнага курсу) робяцца паралельна і асынхронна, і калі абодва вынікі будуць атрыманы, будзе выведзены канчатковы кошт:
findBestPrice("iPhone6")
.thenCombine(lookupExchangeRate(Currency.GBP), this::exchange)
.thenAccept(localAmount -> System.out.printf("It will cost you %f GBP\n", localAmount));
private CompletableFuture findBestPrice(String product Name) {
return CompletableFuture.supplyAsync(() -> priceFinder.findBestPrice(productName));
}
private CompletableFuture lookupExchangeRate(Currency localCurrency) {
return CompletableFuture.supplyAsync(() -> exchangeService.lookupExchangeRate(Currency.USD, localCurrency));
}
JSE
Common Annotations
@Generated
Пазначае зыходны код, які быў згенераваны:
@Generated(“com.sun.xml.rpc.AProcessor”)
public interface StockQuoteService extends java.rmi.Remote {
this.context = context;
}
@ManagedBean
Выкарыстоўваецца для пазначэньня аб'ектаў, якія могуць кіравацца кантэйнэрам:
@ManagedBean(“cart”)
public class ShoppingCart {
...
}
@PostConstruct і @PreDestroy
@PostConstruct выкарыстоўваецца для пазначэньня мэтаду, які будзе выкліканы пасьля ўсіх іньекцый, але перад тым, як бін будзе прадстаўлены кантэйнэрам для выкарыстаньня. А @PreDestroy выкарыстоўваецца для пазначэньня мэтаду, які будзе выкліканы непасрэдна перад тым, як кантэйнэр вынішчыць бін, для вызваленьня папярэдне занятых рэсурсаў. Мэтады, пазначаныя гэтымі анатацыямі, павінны вяртаць void, не кідаць checked выключэньняў, не быць статычнымі, а таксама не прымаць аргумэнтаў, за выключэньнем EJB-інтэрсэптэраў, калі яны прымаюць аргумэнт InvocationContext.
...
@Resource
private void setMyDB(DataSource ds) {
myDB = ds;
}
@PostConstruct
private void initialize() {
// Initialize the connection object from the DataSource
connection = myDB.getConnection();
}
@PreDestroy
private void cleanup() {
// Close the connection to the DataSource.
connection.close();
}
private DataSource myDB;
private Connection connection;
...
@Resource і @Resources
@Resource выкарыстоўваецца для пазначэньня спасылкі на рэсурс. Калі выкарыстоўваецца перад полем альбо сэттэрам, кантэйнэр зробіць іньекцыю адпаведнага значэньня ў час ініцыіраваньня праграмы. Калі выкарыстоўваецца перад клясам, гэта азначае, што праграма будзе "шукаць" значэньне ў часе сваёй працы.
@Resource(name=”customerDB”)
private DataSource myDB;
Калі ж трэба пазначыць некалькі рэсурсаў, выкарыстоўваецца @Resources:
@Resources ({
@Resource(name=”myDB” type=javax.sql.DataSource),
@Resource(name=”myMQ” type=javax.jms.ConnectionFactory)
})
public class CalculatorBean {
//...
}
@DeclareRoles
Выкарыстоўваецца для аб'яўленьня роляў праграмы. (ня вельмі разумею сэнс)
@DeclareRoles("BusinessAdmin")
public class Calculator {
public void convertCurrency() {
if (x.isUserInRole(“BusinessAdmin”)) {
....
}
}
...
}
@RolesAllowed
Выкарыстоўваецца для пазначэньня роляў, пад якімі дазваляецца выкананьне мэтадаў. Можа стаяць перад клясай і перад мэтадам. Калі ўжываецца перад клясай, ужываецца да ўсіх яе мэтадаў. Калі ўжываецца і перад клясай, і перад мэтадамі, тады анатацыя перад мэтадам перакрывае анатацыю перад клясай.
@RolesAllowed("Users")
public class Calculator {
@RolesAllowed(“Administrator”)
public void setNewRate(int rate) {
...
}
...
}
@PermitAll
Выкарыстоўваецца каб пазначыць, што выкананьне мэтадаў дазваляецца любым ролям. Можа стаяць перад клясай і перад мэтадам.
@RolesAllowed("Users")
public class Calculator {
@RolesAllowed(“Administrator”)
public void setNewRate(int rate) {
...
}
@PermitAll
public long convertCurrency(long amount) {
...
}
...
}
@DenyAll
Выкарыстоўваецца каб пазначыць, што выкананьне мэтадаў забараняецца незалежна ад ролі. Можа стаяць перад клясай і перад мэтадам.
@RolesAllowed("Users")
public class Calculator {
@RolesAllowed(“Administrator”)
public void setNewRate(int rate) {
...
}
@DenyAll
public long convertCurrency(long amount) {
...
}
...
}
@DataSourceDefinition і @DataSourceDefinitions
@DataSourceDefinition выкарыстоўваецца для аб'яўленьня DataSource кантэйнэра і для рэгістрацыі яго ў JNDI.
@DataSourceDefinition(name="java:global/MyApp/MyDataSource",
className="org.apache.derby.jdbc.ClientDataSource",
url="jdbc:derby://localhost:1527/myDB",
user="lance",
password="secret")
альбо:
@DataSourceDefinition(name="java:global/MyApp/MyDataSource",
className="com.foobar.MyDataSource",
portNumber=6689,
serverName="myserver.com",
user="lance",
password="secret")
Калі ж трэба аб'явіць некалькі DataSource, выкарыстоўваецца @DataSourceDefinitions:
@DataSourceDefinitions ({
@DataSourceDefinition(name="java:global/MyApp/MyDataSource",
className="com.foobar.MyDataSource",
portNumber=6689,
serverName="myserver.com",
user="lance",
password="secret"),
@DataSourceDefinition(name="java:global/MyApp/MyDataSource",
className="org.apache.derby.jdbc.ClientDataSource",
url="jdbc:derby://localhost:1527/myDB",
user="lance",
password="secret")
})
public class CalculatorBean {
...
}
JDBC
JNDI
JAXP
JAXB
StAX
JAAS
JMX
JAF
JEE
Рэсурсы
Books on Java EE and Related Technologies
Screencasts: Adam Bien (у храналягічным парадку)
IntelliJ IDEA: JavaEE 7 Screencasts
ZEEF: Arjan Tijms, Abhishek Gupta
Спэцыфікацыі
Зялёным тлом пазначаныя спэцыфікацыі, якія ўвайшлі ў Web Profile (JEE 6 і JEE 7) – гэта падмноства спэцыфікацыяў з JEE, актуальнае для распрацоўкі сеціўных праграмаў.
| Тэхналёгія | J2EE 1.4 (11.11.03) JSR 151 | Tutorial |
JEE 5 (11.05.06) JSR 244 | Tutorial |
JEE 6 (10.12.09) JSR 316 | Tutorial |
JEE 7 (16.06.13) JSR 342 | Tutorial |
||||
|---|---|---|---|---|---|---|---|---|
| Вэрсія | JSR | Вэрсія | JSR | Вэрсія | JSR | Вэрсія | JSR | |
| Тэхналёгіі сеціўных праграмаў: | ||||||||
| Java Servlet | 2.4 | JSR 154 | 2.5 | JSR 154 | 3.0 | JSR 315 | 3.1 | JSR 340 |
| JSF | 1.1 | JSR 127 | 1.2 | JSR 252 | 2.0 | JSR 314 | 2.2 | JSR 344 |
| EL | 2.2 | JSR 245 | 3.0 | JSR 341 | ||||
| JSP | 2.0 | JSR 152 | 2.1 | JSR 245 | 2.2 | JSR 245 | 2.3 | JSR 245 |
| JSTL | 1.1 | JSR 52 | 1.2 | JSR 52 | 1.2 | JSR 52 | 1.2 | JSR 52 |
| Java API for WebSocket | 1.0 | JSR 356 | ||||||
| Тэхналёгіі enterprise праграмаў: | ||||||||
| Dependency Injection | 1.0 | JSR 330 | 1.0 | JSR 330 | ||||
| Contexts and Dependency Injection | 1.0 | JSR 299 | 1.1 | JSR 346 | ||||
| Bean Validation | 1.0 | JSR 303 | 1.1 | JSR 349 | ||||
| EJB | 2.1 | JSR 153 | 3.0 | JSR 220 | 3.1 | JSR 318 | 3.2 | JSR 345 |
| JPA | 1.0 | JSR 220 | 2.0 | JSR 317 | 2.1 | JSR 338 | ||
| JTA | 1.0 | 1.1 | JSR 907 | 1.1 | JSR 907 | 1.2 | JSR 907 | |
| JMS | 1.1 | 1.1 | JSR 914 | 1.1 | JSR 914 | 2.0 | JSR 343 | |
| JavaMail API | 1.3 | 1.4 | JSR 919 | 1.4 | JSR 919 | 1.5 | JSR 919 | |
| JCA | 1.5 | JSR 112 | 1.5 | JSR 112 | 1.6 | JSR 322 | 1.7 | JSR 322 |
| Concurrency Utilities for Java EE | 1.0 | JSR 236 | ||||||
| Тэхналёгіі сеціўных сэрвісаў: | ||||||||
| Web Services | 1.0 | 1.2 | JSR 109 | 1.3 | JSR 109 | 1.3 | JSR 109 | |
| Web Services Metadata | 2.0 | JSR 181 | 2.1 | JSR 181 | 2.1 | JSR 181 | ||
| JAX-RS | 1.1 | JSR 311 | 2.0 | JSR 339 | ||||
| JSON-P | 1.0 | JSR 353 | ||||||
| JAX-WS | 2.0 | JSR 224 | 2.2 | JSR 224 | 2.2 | JSR 224 | ||
| JAX-RPC | 1.1 | 1.1 | JSR 101 | 1.1 | JSR 101 | 1.1 | JSR 101 | |
| JAXM | 1.1 | 1.3 | JSR 67 | 1.3 | JSR 67 | |||
| JAXR | 1.0 | 1.0 | JSR 93 | 1.0 | JSR 93 | 1.0 | JSR 93 | |
| Тэхналёгіі JSE, якія маюць дачыненьне да JEE: | ||||||||
| Common Annotations | 1.0 | JSR 250 | 1.1 | JSR 250 | 1.2 | JSR 250 | ||
| JDBC | 3.0 | JSR 54 | 3.0 | JSR 54 | 4.0 | JSR 221 | 4.1 | JSR 221 |
| JNDI | 1.2 | |||||||
| JAAS | 1.0 | 1.0 | 1.0 | 1.0 | ||||
| JAXB | 2.0 | JSR 222 | 2.2 | JSR 222 | 2.2 | JSR 222 | ||
| JAXP | 1.2 | 1.2 | 1.2 | 1.3 | JSR 206 | |||
| StAX | 1.0 | JSR 173 | 1.0 | JSR 173 | 1.0 | JSR 173 | ||
| JMX | 1.2 | JSR 3 | ||||||
| JAF | 1.0 | 1.1 | JSR 925 | 1.1 | JSR 925 | 1.1 | JSR 925 | |
Дэскрыптары разгортваньня
my-app
`-- src
`-- main
|-- java
| `...
|-- resources
| |
| `--META-INF
| |-- application.xml - JavaEE
| |-- application-client.xml - JavaEE
| |-- persistence.xml - JPA
| `-- ra.xml - JCA
`-- webapp
|
`--WEB-INF
|-- beans.xml - CDI
|-- ejb-jar.xml - EJB
|-- faces-config.xml - JSF
|-- validation.xml - Beans Validation
|-- web.xml - Servlet
|-- web-fragment.xml - Servlet
`-- webservices.xml - Web-services SOAP
web.xml
<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
</web-app>
beans.xml
<beans xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/beans_1_1.xsd"
bean-discovery-mode="all">
</beans>
faces-config.xml
<faces-config version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-facesconfig_2_2.xsd">
</faces-config>
persistence.xml
<persistence version="2.1"
xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="primary">
<!-- If you are running in a production environment, add a managed
data source, this example data source is just for devleopment and testing! -->
<!-- The datasource is deployed as WEB-INF/hibernate4-quickstart-ds.xml, you can
find it in the source at src/main/webapp/WEB-INF/hibernate4-quickstart-ds.xml -->
<jta-data-source>java:jboss/datasources/Hibernate4QuickstartDS</jta-data-source>
<properties>
<!-- Properties for Hibernate -->
<property name="hibernate.hbm2ddl.auto" value="create-drop" />
<property name="hibernate.show_sql" value="false" />
</properties>
</persistence-unit>
</persistence>
Біны і CDI
Амаль любая Java-кляса з канструктарам без парамэтраў, альбо з канструктарам пазначаным анатацыяй @Inject, зьяўляецца кампанэнтам, кіруемым кантэйнэрам (managed bean). Акрамя патрабаваньня да канструктараў ёсьць яшчэ некалькі патрабаваньняў да кіруемых біноў:
- яны павінны быць верхняга ўзроўню (top-level), то бок не nested;
- ня могуць быць не-статычнымі ўнутранымі клясамі (з унутраных клясаў толькі статычныя могуць быць кіруемымі бінамі);
- яны павінны быць пэўнымі клясамі (не абстрактнымі), альбо мець анатацыю
@Decorator; - не павінны быць пазначаныя як EJB праз адпаведную анатацыю, альбо праз файл
ejb-jar.xml.
Калі кляса адпавядае ўсім вышэйпералічаным патрабаваньням, яе жыцьцёвым цыклям можа кіраваць кантэйнэр, а таксама рабіць іньекцыю (inject) у яе іншых клясаў ці біноў.
Жыцьцёвы цыкл кампанэнтаў
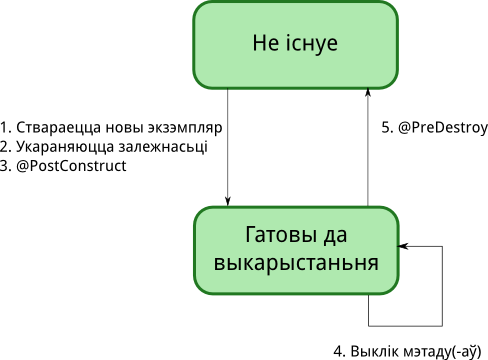
Вобласьці бачнасьці і кантэкст
Кожны экзэмпляр кіруемага біна, які быў створаны кантэйнэрам праз службу CDI, зьяўляецца кантэкстуальным экзэмплярам, то бок ён існуе выключна ў межах пэўнага кантэксту і доступ да яго маюць толькі тыя іншыя аб'екты, якія існуюць у межах таго ж самага кантэксту. Кантэйнэр аўтаматычна стварае экзэмпляр кіруемага біна, калі нейкі іншы аб'ект мае ў ім патрэбу. Кантэйнэр разбурае раней створаны ім экзэмпляр, калі той кантэкст заканчваецца.
Усяго існуе 5 убудаваных кантэкстаў:
| Кантэкст | Анатацыя | Працягласьць |
|---|---|---|
| Запросу | @RequestScoped |
Узаемадзеяньне аднаго карыстальніка з праграмай цягам аднаго HTTP-запыту. |
| Сэсіі | @SessionScoped |
Узаемадзеяньне аднаго карыстальніка з праграмай цягам шэрагу HTTP-запыту, якія складаюць адну сэсію з праграмай. |
| Праграмы | @ApplicationScoped |
Падзяляе стан паміж усімі карыстальнікамі праграмы цягам усяго жыцьця праграмы. |
| Залежны | @Dependent |
Змоўчны кантэкст, калі яўна не пазначаны. Азначае, што аб'ект створаны, каб служыць дакладна аднаму кліенту (іншаму біну), і жыве столькі ж, колькі і кліент. |
| Дыялёгу | @ConversationScoped |
Працягласьць гэтага кантэксту пашыраецца на шэраг HTTP-запытаў аднаго карыстальніка. Дакладная працягласьць гэтага шэрагу вызначаецца распрацоўшчыкам, але не можа "перасякаць" межы адной сэсіі. |
Request scoped біны альбо залежныя біны, чый кліент зьяўляецца request scoped біном, могуць не быць serizalizable. Астатнія кантэкстуальныя біны (кантэксту сэсіі, праграмы, дыялёгу, а таксама залежныя ад такіх біноў) павінны быць serizalizable.
@Inject
Як мы ўжо пазначылі вышэй, кантэйнэр акрамя кіраваньня жыцьцём біна можа ўбудоўваць (рабіць іньекцыю) у яго неабходныя яму рэсурсы альбо іншыя біны. Што можа ўбудоўвацца:
- амаль любая Java-кляса;
- Session beans;
- JavaEE-рэсурсы: крыніцы даных (data sources), JMS-topics, чэргі, фабрыкі злучэньняў (conncetion factories) і падобнае;
- persistent conexts (аб'екты
EntityManagerз JPA); - палі-вытворцы (producer fields);
- аб'екты, якія вяртаюцца мэтадамі-вытворцамі (producer methods);
- спасылкі на вэб-сэрвісы;
- спасылкі на адлеглыя EJB.
Іньекцыя робіцца пры дапамозе анатацыі @Inject:
import javax.inject.Inject;
public class Printer {
@Inject Greeting greeting;
...
}
У дадзеным прыкладзе аб'ект Greeting будзе аўтаматычна падстаўлены (створаны новы альбо ўзяты існуючы, калі ў дадзеным кантэксьце ён ужо існуе) у поле greeting ствараемага экзэмпляра клясы Printer. Пры гэтым нават не абавязкова мець public setter да гэтага поля, кантэйнэр зробіць іньекцыю нават у прыватнае поле.
Кваліфікатары
Кантэйнэр спрабуе знайсьці кандыдата для іньекцыі па тыпу аб'екта. Калі ж кантэйнэр знаходзіць некалькі раўназначных кандыдатаў, ён кіне выключэньне. У наступным прыкладзе кантэйнэр ня здолее выбраць паміж SuperCar і CrossOver для іньекцыі ў поле car і кіне выключэньне:
public class SuperCar implements Car {...}
public class Crossover implements Car {...}
public class Garage {
@Inject Car car;
}
Для таго, каб вырашыць гэтую праблему, служаць кваліфікатары – анатацыі-маркеры, якія аб'яўляюцца пры дапамозе анатацыі @Qualifier:
@Qualifier
@Retention(RUNTIME)
@Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Parkable {}
Тады вышэйзгаданы канфліктны прыклад можна перапісаць наступным чынам:
public class SuperCar implements Car {...}
@Parkable
public class Crossover implements Car {...}
public class Garage {
@Inject @Parkable Car car;
}
Тым самым мы кажам кантэйнэру, што для іньекцыі ў дадзеным месцы падыходзіць не любы Car, але толькі той, які пазначаны анатацыяй-маркерам @Parkable. Кантэйнэр здолее адназначна выбраць адзін кандыдат для іньекцыі і выключэньня ня будзе.
Кваліфікатары можна камбінаваць, то бок пазначаць адну і тую ж клясу ці месца іньекцыі некалькімі кваліфікатарамі. Акрамя гэтага іх можна парамэтрызаваць. Прывядзем ніжэй 2 варыянты рэалізаваць адну і тую ж задуму. Першы варыянт пры дапамозе множных кваліфікатараў:
@Qualifier @Retention(RUNTIME) @Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Number {}
@Qualifier @Retention(RUNTIME) @Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Odd {}
public class Game {
@Inject @Number @Odd int num;
...
}
Другі варыянт пры дапамозе аднаго кваліфікатара, але з парамэтрамі:
@Qualifier @Retention(RUNTIME) @Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Number {
boolean odd();
}
public class Game {
@Inject @Number(odd = true) int num;
...
}
@Default
@Default – гэта ўбудаваны і пры гэтым змоўчны кваліфікатар. То бок, калі пры аб'яўленьні біна не пазначана ніякага яўнага кваліфікатара, ён аўтаматычна пазначаецца кваліфікатарам @Default. Калі ў момант убудаваньня залежнасьці, кантэйнэр вызначыць некалькі кандыдатаў, пры гэтым усе акрамя аднаго будуць пазначаныя яўнымі кваліфікатарамі, а адзін не будзе пазначаны, а таксама ў пункце ўбудаваньня не будзе пазначана яўнага кваліфікатара, тады кантэйнэр ня кіне выключэньне і падставіць @Default-кандыдата.
@Alternative
Анатацыяй @Alternative можна пазначыць не прыярытэтны, а наадварот непажаданы кандыдат(-аў) для іньекцыі:
@Alternative
public class SuperCar implements Car {...}
public class Crossover implements Car {...}
public class Garage {
@Inject Car car;
}
Адзіны спосаб, каб кантэйнэр усё ж мог яго выбраць для іньекцыі – актываваць яго ў дэскрыптары beans.xml:
<beans xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/beans_1_1.xsd"
version="1.1"
bean-discovery-mode="all">
<alternatives>
<class>some.package.SuperCar</class>
</alternatives>
</beans>
@Vetoed
Можна таксама ўвогуле выключыць нейкую клясу пры абраньні кандыдатаў для іньекцыі праз анатацыю @Vetoed.
@Any і выбар з альтэрнатываў
Анатацыяй @Any звычайна пазначаецца месца іньекцыі і кажа кантэйнэру, каб ён убудаваў усе магчымыя кандыдаты (сьпіс). Пазьней можна прабягацца па гэтаму сьпісу і выбіраць патрэбны кандыдат у рантайм:
@Named("atm")
public class AutomatedTellerMachineImpl implements AutomatedTellerMachine {
@Inject @Any
private Instance allTransports;
private ATMTransport transport;
private boolean useJSON = true;
private boolean behindFireWall = true;
@PostConstruct
protected void init() {
ATMTransport soapTransport, jsonTransport, standardTransport;
standardTransport = allTransports.select(new AnnotationLiteral() {}).get();
jsonTransport = allTransports.select(new AnnotationLiteral() {}).get();
soapTransport = allTransports.select(new AnnotationLiteral() {}).get();
if (!behindFireWall) {
transport = standardTransport;
} else {
if (useJSON) {
transport = jsonTransport;
} else {
transport = soapTransport;
}
}
}
}
@Named
Анатацыяй @Named пазначаюцца біны, да якіх павінны мець доступ вью па іх імёнах:
@Named
@RequestScoped
public class Game implements Serializable {
...
}
<!DOCTYPE html>
<head>...</head>
<body>
<div>
Your guess:
<h:inputText id="inputGuess" value="#{game.guess}"
required="true" size="3"
disabled="#{game.number eq game.guess}"
validator="#{game.validateNumberRange}" />
<h:commandButton id="guessButton" value="Guess"
action="#{game.check}"
disabled="#{game.number eq game.guess}" />
</div>
</body>
</html>
Улічваючы, што змоўчным кантэкстам (ці вобласьцю бачнасьці) біна, калі яўна не пазначана, зьяўляецца @Dependent, што не падыходзіць у якасьці мадэлі для вью (таму што даныя, якія туды трапілі з вью, будуць адразу страчаныя), і разам з анатацыяй @Named заўсёды прыходзіцца пазначаць анатацыю @RequestScoped, стандартам CDI была ўведзеная дапаможная анатацыя @Model, якая проста камбінуе @Named і @RequestScoped:
@Model
public class Game implements Serializable {
...
}
@New
Калі ў месцы ўбудаваньня залежнасьці пажадана мець заўсёды ўнікальны аб'ект, які ня будзе падзяляцца з іншымі кантэкстамі (аб'ектамі), можна выкарыстоўваць анатацыю @New. У гэтым выпадку кантэйнэр будзе заўсёды ствараць новы аб'ект, а не спрабаваць падставіць ужо існуючы.
@Produces і @Disposes
Анатацыя @Produces прадстаўляе мэханізм рабіць іньекцыі ня толькі біноў і JEE-рэсурсаў. Такім чынам могуць быць іньектаваны:
- прымітыўныя тыпы (
int,booleanі інш.); - масівы і калекцыі;
- аб'екты кшталту
java.util.Dateальбоjava.lang.String; - аб'екты, чыя дакладная кляса будзе вядома толькі ў часе выкананьня праграмы;
- аб'екты, якія патрабуюць дадатковай ініцыялізацыі.
Некалькі прыкладаў:
@Qualifier @Retention(RUNTIME) @Target({ TYPE, METHOD, PARAMETER, FIELD })
public @interface Random {}
@ApplicationScoped
public class Generator implements Serializable {
private java.util.Random random = new java.util.Random(System.currentTimeMillis());
private int maxNumber = 100;
@Produces @Random // Гэты мэтад стварае экзэмпляр Random
int next() {
return random.nextInt(maxNumber - 1) + 1;
}
}
@SessionScoped
public class Game implements Serializable {
@Inject @Random // У гэтае поле падстаўляецца папярэдне створаны экзэмпляр Random
Instance randomNumber; // Instance - гэта сьпіс, які мае ітэратар. У агульным
// выпадку кандыдатаў на падстаноўку можа быць некалькі
// (некалькі @Default), тады сюды падставіцца не адно
// значэньне, а ўсе знойдзеныя. Можна рабіць так
// randomNumber.iterator().next()
...
}
...
@Produces
public List getGreetings() {
List response = new ArrayList();
...
return response;
}
@Inject List list;
...
@Produces-мэтад можа ў якасьці аргумэнту прымаць InjectionPoint – доступ да асяродку іньекцыі:
class Loggers {
@Produces Logger getLogger(InjectionPoint injectionPoint) {
return Logger.getLogger( injectionPoint.getMember().getDeclaringClass().getSimpleName() );
}
}
@SessionScoped
public class Permissions implements Serializable {
@Inject Logger log; // Так можна рабіць у кожным месцы, дзе патрэбны логер
// і кожны раз будзе стварацца логер для адпаведнай клясы
...
}
З-за таго, што ў выпадку мэтаду-вытворцы кантэйнэр губляе кіраваньне вырашэньнем залежнасьцей і іх вобласьці бачнасьці, трэба быць уважлівым, каб не парушыць цэльнасьць. Разгледзім такі прыклад:
@Produces @Preferred @SessionScoped
public PaymentStrategy getPaymentStrategy(CreditCardPaymentStrategy ccps,
CheckPaymentStrategy cps,
PayPalPaymentStrategy ppps) {
switch (paymentStrategy) {
case CREDIT_CARD: return ccps;
case CHEQUE: return cps;
case PAYPAL: return ppps;
default: return null;
}
}
Калі адзін ці некалькі аргумэнтаў мэтаду getPaymentStrategy будуць request-scoped, у пэўны момант жыцьця сэсіі адпаведныя аб'екты ўжо могуць не існаваць. Каб пазьбегнуць такой сытуацыі, трэба даваць максымальны кантроль кантэйнэру, які дакладна не дапусьціць яе:
@Produces @Preferred @SessionScoped
public PaymentStrategy getPaymentStrategy(@Dependent CreditCardPaymentStrategy ccps,
@Dependent CheckPaymentStrategy cps,
@Dependent PayPalPaymentStrategy ppps) {
switch (paymentStrategy) {
case CREDIT_CARD: return ccps;
case CHEQUE: return cps;
case PAYPAL: return ppps;
default: return null;
}
}
У дадатак да асаблівага мэханізму стварэньня аб'екта ў CDI існуе асаблівы мэханізм да разбурэньня раней створанага кантэйнэрам аб'екта – анатацыя @Dispose. Гэты спосаб патрэбны ў тым выпадку, калі аб'ект павінен быць ня проста выкінуты, але патрэбна яшчэ вызваліць адкрытыя ім рэсурсы:
@Produces @RequestScoped
Connection connect(User user) {
return createConnection(user.getId(), user.getPassword());
}
void close(@Disposes Connection connection) {
connection.close();
}
Падзеі
CDI-падзеі прадстаўляюць спосаб камунікацыі паміж кампанэнтамі праграмы без убудаваньня залежнасьцяў.
У вытворцы падзеяў робіцца іньекцыя падзеяў і выклікаецца мэтад fire, каб даслаць іх слухацелям падзеяў:
@Inject Event event;
...
event.fire(new LoggedInEvent(username));
Слухацелі аб'яўляюць мэтад, які будзе прымаць дасланыя падзеі:
void onLoggedIn(@Observes LoggedInEvent event) {
...
}
Па змоўчваньні, калі дасылаецца падзея, а адпаведны экзэмпляр слухацеля(-ў) яшчэ ня быў створаны, кантэйнэр яго створыць. Гэта можа быць не пажадана. Таму слухацель можа быць умоўным:
public void refreshOnDocumentUpdate(@Observes(receive=IF_EXISTS) @Updated Document doc) {
...
}
Перахопнікі
Перахопнікі выкарыстоўваюць для ўбудаваньня скразнога функцыяналу скрозь аб'екты рознага тыпу і прызначэньня. Напрыклад, лагіраваньне альбо функцыянал па бясьпецы. Робіцца гэта для таго, каб ён утрымліваўся ў адным месцы, а ня быў раскіданы па ўсяму праекту. Аб'ектамі, у якія можна ўстаўляць перахопнікі, зьяўляюцца любыя кіруемыя біны – CDI-біны, EJB, RESTful-сэрвісы і іншае.
Іншымі словамі перахопнікі – гэта клясы, чые мэтады выклікаюцца, калі выклікаюцца мэтады мэтавых клясаў, альбо адбываюцца падзеі жыцьцёвага цыкла гэтых клясаў, альбо адбываюцца таймаўты EJB-мэтадаў.
Каб убудаваць перахопнік, спачатку трэба стварыць злучальнік паміж перахопнікам і бізнэс-клясай. Для гэтага служыць анатацыя @InterceptorBinding:
@Inherited @Retention(RUNTIME) @Target({METHOD, TYPE})
@InterceptorBinding
public @interface Logging {
}
Пасьля гэтага ствараем клясу самога перахопніка і аб'яўляем у ёй мэтады-перахопнікі (ня больш за 1 кожнага тыпу):
@Interceptor
@Logging // Гэта злучальнік, які мы аб'явілі раней
public class LoggingInterceptor {
@AroundInvoke
public Object log(InvocationContext context) throws Exception {
String name = context.getMethod().getName();
String params = context.getParameters().toString();
//. . .
return context.proceed(); // Выклік бізнэс-лёгікі
}
}
І напрыканцы пазначаем анатацыяй злучальніка бізнэс-клясу (тады перахоплівацца будуць усе мэтады бізнэс-клясы):
@Logging
public class SimpleGreeting {
...
}
Альбо толькі пэўны мэтад(ы) бізнэс-клясы (тады будуць перахоплівацца толькі пазначаныя мэтады):
public class SimpleGreeting {
@Logging
public String greet(String name) {
...
}
}
Мэтады-перахопнікі бываюць наступных тыпаў:
@AroundConstruct– перахопнікі канструктараў;@AroundInvoke– перахопнікі мэтадаў;@PostConstructі@PreDestroy– перахопнікі падзеяў жыцьцёвага цыкла;@AroundTimeout– перахопнікі таймаўтаў EJB-мэтадаў;
Па змоўчваньні перахопнікі не актыўныя, каб актываваць іх, трэба дадаць адпаведныя інструкцыі ў дэскрыптар beans.xml:
<beans xmlns='http://java.sun.com/xml/ns/javaee'>
<interceptors>
<class>org.example.TransactionInterceptor</class>
<class>org.example.LoggingInterceptor</class>
</interceptors>
</beans>
Такія перахопнікі будуць актыўныя для архіву, які будзе ўтрымліваць гэты дэскрыптар. Альтэрнатыўным спосабам актываваць перахопнік зьяўляецца ўжываньне анатацыі @Priority пры яго аб'яўленьні:
@Priority(Interceptor.Priority.APPLICATION + 10)
@Interceptor
@Logging
public class LoggingInterceptor {
...
}
Перахопнік, актываваны такім чынам, будзе актыўным ува ўсёй праграме, незалежна ад таго, у якім архіве ён утрымліваецца. Перадвызначаныя канстанты для прыярытэтаў:
| Прыярытэт | Значэньне |
|---|---|
Interceptor.Priority.PLATFORM_BEFORE |
0 |
Interceptor.Priority.LIBRARY_BEFORE |
1000 |
Interceptor.Priority.APPLICATION |
2000 |
Interceptor.Priority.LIBRARY_AFTER |
3000 |
Interceptor.Priority.PLATFORM_AFTER |
4000 |
Чым меншае значэньне, тым раней у чарадзе перахопнікаў ён будзе выкліканы, калі некалькі перахопнікаў вызначаныя для аднаго і таго ж мэтаду. Калі ж перахопнікі актываваныя праз дэскрыптар, тады пасьлядоўнасьць іх выклікаў вызначаецца пасьлядоўнасьцю, зь якой яны зьмяшчаюцца ў дэскрыптары.
Дэкаратары
Сутнасьць дэкаратараў падобна да сутнасьці перахопнікаў, але калі перахопнікі ня ведаюць і не турбуюцца пра бізнеэс-лёгіку, якую яны абгортваюць, то дэкаратары ствараюцца для аб'ектаў пэўнага тыпу і для пашырэньня іх бізнэс-лёгікі. Дэкаратар – гэта бін, які рэалізуе дэкаруемы ім бін (інтэрфэйс) і пазначаецца стэрэатыпнай анатацыяй @Decorator
@Decorator
class TimestampLogger implements Logger {
@Inject @Delegate Logger logger;
public void log(String message) {
logger.log( timestamp() + ': ' + message);
}
}
Дэкаратар павінен рэалізоўваць адзіны пункт іньекцыі дэлегата – біна, які ён дэкарыруе (радок 4). Усе выклікі мэтадаў дэлегата, якія рэалізуе дэкаратар, будуць накіраваны да дэкаратара, які ў сваю чаргу можа рабіць выклік адпаведных мэтадаў дэлегата (радок 7):
@Decorator
class TimestampLogger implements Logger {
@Inject @Delegate Logger logger;
public void log(String message) {
logger.log( timestamp() + ': ' + message);
}
}
Дэкаратар можа рэалізоўваць ня ўсе мэтады дэлегата і, адпаведна, быць абстрактным. Дэкаратары выклікаюцца пасьля перахопнікаў.
Дэкаратары, як і перахопнікі, па змоўчваньні не актыўныя, каб актываваць іх, трэба дадаць адпаведныя інструкцыі ў дэскрыптар beans.xml:
<beans xmlns='http://java.sun.com/xml/ns/javaee'>
<decorators>
<class>org.example.TimestampLogger</class>
</decorators>
</beans>
Альбо пазначыць іх анатацыяй @Priority.
Стэрэатыпы
Стэрэатыпы – гэта мэта-анатацыі, якія аб'ядноўваюць іншыя анатацыі. Напрыклад, перадвызначаны стэрэатып @Model:
@Named
@RequestScoped
@Stereotype
@Target({TYPE, METHOD})
@Retention(RUNTIME)
public @interface Model {}
Ён аб'ядноўвае анатацыі @Named і @RequestScoped.
AOP
Валідацыя біноў
EJB
Enterprise JavaBeans 3.1 with Contexts and Dependency Injection: The Perfect Synergy
JPA
JSF
JSF2: How to Create a Global Ajax Status Indicator
Што можна наладжваць праз faces-config.xml
Разработка JSF приложений при помощи IntelliJ Idea. Часть 2: Разработка простого приложения
prettyfaces – The open-source /url/#{rewriting} solution for Servlet, JSF, and Java EE
PrimeFaces
OmniFaces
JAX-RS
GET / POST with RESTful Client API
Java EE 7: Using JAX-RS Client API to consume RESTful Web Services
У ніжэй прыведзеным прыкладзе пры звароце да RESTful GET-рэсурсу адбудзецца аўтаматычнае канвэртацыя Java-аб'екту ў JSON-фармат пры дапамозе RESTEasy. Галоўнае, каб бін Member быў пазначаны JAXB-анатацыяй @XmlRootElement.
@GET
@Produces(MediaType.APPLICATION_JSON)
public List listAllMembers() {
return repository.findAllOrderedByName();
}
Security
Best practice for REST token-based authentication with JAX-RS and Jersey
Java EE 7 / JAX-RS 2.0: Simple REST API Authentication & Authorization with Custom HTTP Header
Simple Java EE (JSF) Login Page with JBoss PicketLink Security
Is your web application secure? HTTP attacks are real, and dangerous
@ServletSecurity
Анатацыя ўзроўню клясы @ServletSecurity, якая прызначана абараняць доступ да сэрвлетаў, мае наступнае вызначэньне:
@ServletSecurity(
httpMethodConstraints = <HttpMethodConstraint[]>,
value = <HttpConstraint>
)
Дзе атрыбут httpMethodConstraints вызначае абмежаваньні для HTTP-мэтадаў, а атрыбут value вызначае абмежаваньні для астатніх HTTP-мэтадаў, якія не былі вызначаныя ў атрыбуце httpMethodConstraints.
Прыклады
Адсутнасьць якіх-кольвечы абмежаваньняў бясьпекі:
@WebServlet("/process")
@ServletSecurity
public class MyServlet extends HttpServlet {
// servlet code...
}
Пазначае неабходнасьць кадаваньня для ўсіх HTTP-мэтадаў:
@WebServlet("/process")
@ServletSecurity(@HttpConstraint(transportGuarantee = TransportGuarantee.CONFIDENTIAL))
public class MyServlet extends HttpServlet {
// servlet code...
}
Забараняе любыя HTTP POST мэтады (адпаведна астатнія HTTP-мэтады дазваляюцца):
@WebServlet("/process")
@ServletSecurity(
httpMethodConstraints = @HttpMethodConstraint(value = "POST",
emptyRoleSemantic = EmptyRoleSemantic.DENY)
)
public class MyServlet extends HttpServlet {
// servlet code...
}
Патрабуе, каб карыстальнік, які робіць запыт да сэрвлету, меў ролю admin (для ўсіх HTTP-мэтадаў):
@WebServlet("/manage")
@ServletSecurity(@HttpConstraint(rolesAllowed = "admin"))
public class AdminServlet extends HttpServlet {
// servlet code...
}
Патрабуе, каб карыстальнік, які робіць запыт да POST і GET мэтадаў сэрвлету, меў ролю admin. Дадаткова пазначае неабходнасьць кадаваньня для ўсіх POST-мэтаду:
@WebServlet("/manage")
@ServletSecurity(
httpMethodConstraints = {
@HttpMethodConstraint(value = "GET", rolesAllowed = "admin"),
@HttpMethodConstraint(value = "POST", rolesAllowed = "admin",
transportGuarantee = TransportGuarantee.CONFIDENTIAL),
}
)
public class AdminServlet extends HttpServlet {
// servlet code...
}
JSON Web Token
Рэалізацыі:
PicketLink
PicketLink – гэта фрэймворк бясьпекі JEE праграмаў. Некаторыя з магчымасьцяў:
- першаклясная падтрымка CDI;
- магчымасьць кіраваць бясьпекай біноў і іх мэтадаў, вьюх, сэрвлэтаў і REST-сэрвісаў;
- API для кіраваньня карыстальнікамі, ролямі і групамі;
- сацыяльны лагін праз Facebook, Twitter, Google+.
Падыходзіць для выпадкаў, калі аўтары праграмы рэалізуюць уласную сыстэму бясьпекі – PicketLink прадстаўляе гатовыя цагліны, зь якіх такую сыстэму можна пабудаваць.
KeyCloak
Fetch Logged In Username in a webapp secured with Keycloak.
SECURITY WITH MICROSERVICES: PROGRAMMATIC SECURITY WITH KEYCLOAK.
SECURING JAX-RS: KEYCLOAK, CDI AND EJB CONFUSION.
TESTING KEYCLOAK INTEGRATION WITH ARQUILLIAN.
PROGRAMMATICALLY ADDING USERS IN KEYCLOAK.
KeyCloak – гэта гатовы-да-выкарыстаньня-з-каробкі Single-Sign-On сэрвэр для мабільных, сеціўных і REST-праграмаў з адкрытым зыходным кодам ад JBoss. Ён прадстаўляе магчымасьці: 1. цэнтральнага кіраваньня карыстальнікамі, ролямі, групамі, сэсіямі; 2. сродкі аўтэнтыфікацыі і аўтарызацыі; 3. сацыяльны лагін.
Усталёўка
Для прастаты у межах дадзенага даведніка разгледзім усталёўку выключна дадатку да WildFly. Па астатнія магчымасьці ўсталёўкі глядзіце афіцыйны даведнік.
-
Першым крокам сьцягваем архіў апошняй вэрсіі з афіцыйнай старонкі: http://keycloak.jboss.org/downloads. Дадатак да WildFly мае ў сваім імені слова overlay, напрыклад
keycloak-overlay-1.9.0.CR1.tar.gz. Распакоўваем зьмесьціва архіву ў<WILDFLY_HOME>і ў кансолі запускаем каманду.
Тым самым мы ўсталявалі KeyCloak у WildFly.bin/jboss-cli.sh --file=bin/keycloak-install.cli
- Наступным крокам трэба ўсталяваць адаптар падтрымкі KeyCloak у сеціўных праграмах адсюль: http://keycloak.jboss.org/downloads.html?dir=0%3Dadapters/keycloak-oidc%3B. Для WildFly 8-ай вэрсіі файл
keycloak-wf8-adapter-dist-1.9.0.CR1.tar.gz, а для 9-ай і 10-ай вэрсіяў файлkeycloak-wildfly-adapter-dist-1.9.0.CR1.tar.gz. Ізноў распакоўваем зьмесьціва архіву ў<WILDFLY_HOME>, стартуем WildFly і ў кансолі запускаем каманду.bin/jboss-cli.sh --file=bin/adapter-install.cli - Апошнім крокам трэба перазапусьціць WildFly і адкрыць старонку http://localhost:8080/auth. KeyCloak не прадстаўляе змоўчнага адміністратара, таму дадзеная старонка першай справай дасьць магчымасьць стварыць такога карыстальніка – увядзіце імя і пароль для яго. Калі ж вы ўсталёўваеце KeyCloak не на лякальнай машыне, тады стварыць першага адміністратара можна толькі пры дапамозе каманднага радка:
bin/add-user.sh -r master -u <username> -p <password>
Наладкі KeyCloak
Каб злучыць сеціўную праграму, якую мы распрацоўваем, з сэрвэрам KeyCloak, трэба выканаць наступныя крокі на баку KeyCloak.
-
Па-першае ствараем у KeyCloak вобласьць (realm), якая будзе ўтрымліваць у сабе ўсе наладкі бясьпекі, якія тычацца менавіта і толькі гэтай праграмы. Для гэтага наводзім курсор мышы на стрэлку ў левым верхнім куце:
Зьявіцца акенца існуючых абласьцей і кнопка для стварэньня новай:
Цісьнем на гэтую кнопку і ствараем новую вобласьць:

-
Наступным крокам ствараем ролю для нашай праграмы. Для гэтага знаходзячыся ў створанай намі вобласьці (далейшыя крокі будуць адбывацца ў межах гэтай вобласьці), цісьнем на пункт мэню Roles у разьдзеле Configure:

На старонцы, якая адкрылася, цісьнем на кнопку Add role:
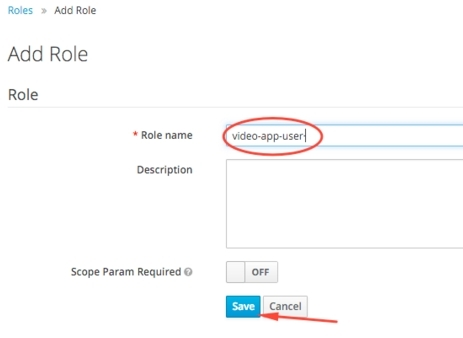
Уводзім назву ролі і цісьнем на кнопку Save:
-
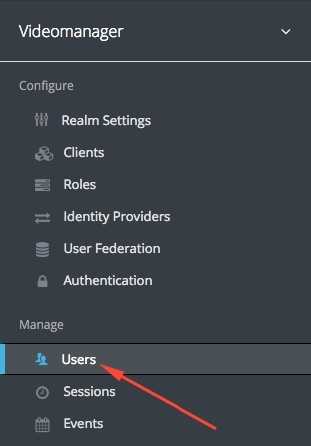
Далей ствараем новага карыстальніка. Цісьнем на пункт мэню Users у разьдзеле Manage:
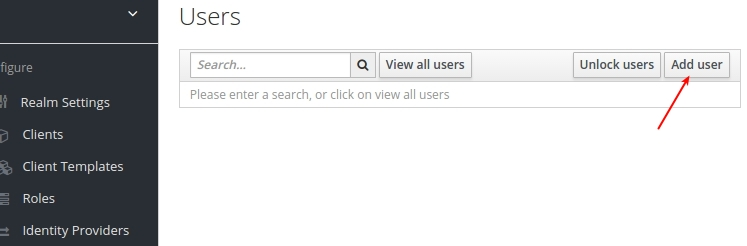
А потым на старонцы, якая адкрылася, цісьнем на кнопку Add user:
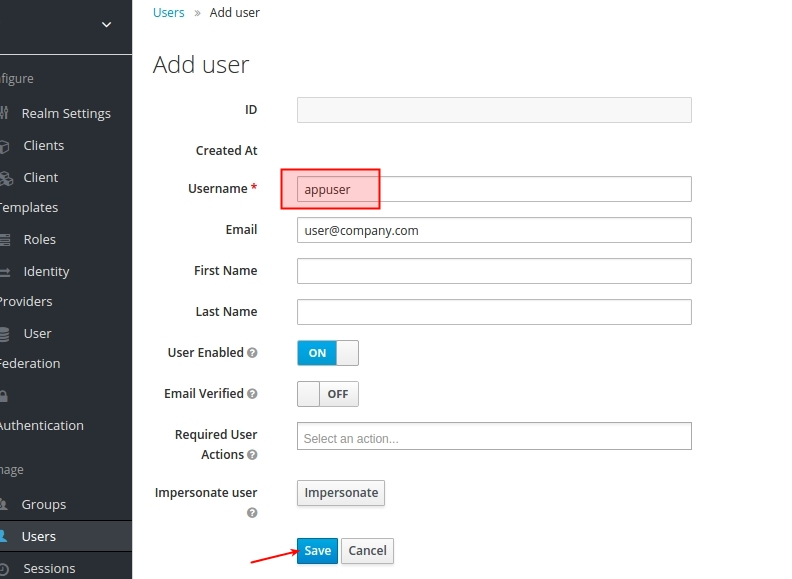
Уводзім даныя карыстальніка і цісьнем на кнопку Save:
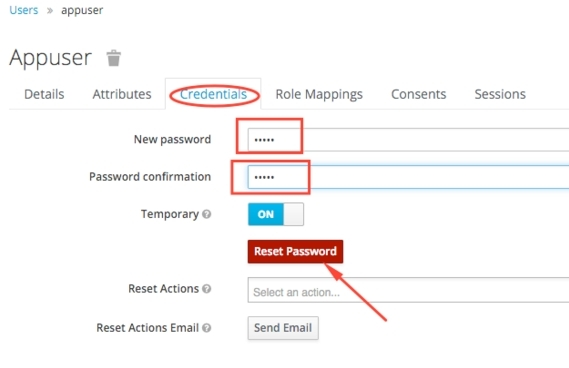
Адкрываем укладку Credentials, уводзім пароль і пацьверджаньне паролю і цісьнем кнопку Reset Password (ня вельмі ўдалая назва):
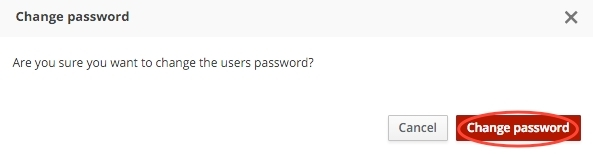
У выніку адкрыецца акенца с запытам пацьвердзіць зьмену паролю, цісьнем кнопку Change Password:
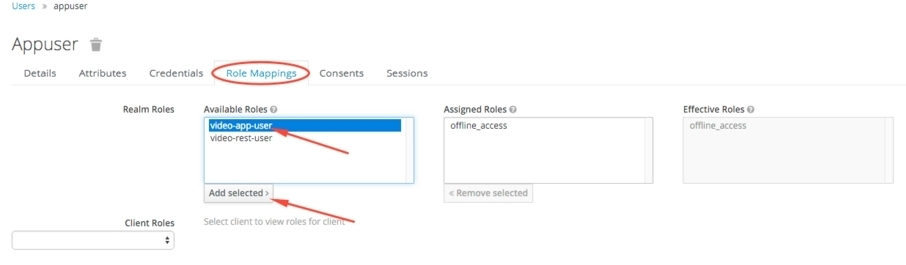
Апошнім крокам злучаем карыстальніка з роляй, якую мы стварылі на папярэднім кроку. Адкрываем укладку Role Mappings, абіраем створаную раней ролю ў сэкцыі Available Roles і цісьнем кнопку Add Selected:
Зьмены захаваюцца аўтаматычна.
-
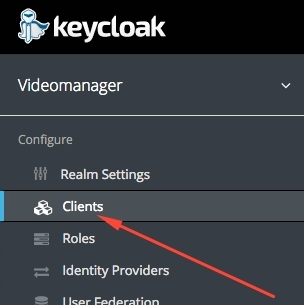
Наступным крокам вызначаем нашу праграму ў якасьці кліента KeyCloak. Цісьнем на пункт мэню Clients у разьдзеле Configure:
А потым на старонцы, якая адкрылася, цісьнем на кнопку Create:

Уводзім атрыбуты нашага кліента (ID, URL для вяртаньня пасьля аўтэнтыфікацыі і тып доступу) і цісьнем на кнопку Save:

Наладкі праграмы
Наладкі праграмы трохі адрозьніваюцца ў залежнасьці ад тэхналёгій, якія ў ёй выкарыстоўваюцца.
- Па-першае, калі гэта Java-кліент, трэба дадаць залежнасьці ў maven-канфігурацыю:
-
Наступным крокам вяртаемся на UI KeyCloak, цісьнем на пункт мэню Clients у разьдзеле Configure, у падмэню выбіраем Installation і на старонцы, якая адкрыецца, у полі Format Option выбіраем пункт Keycloak OIDC JSON:
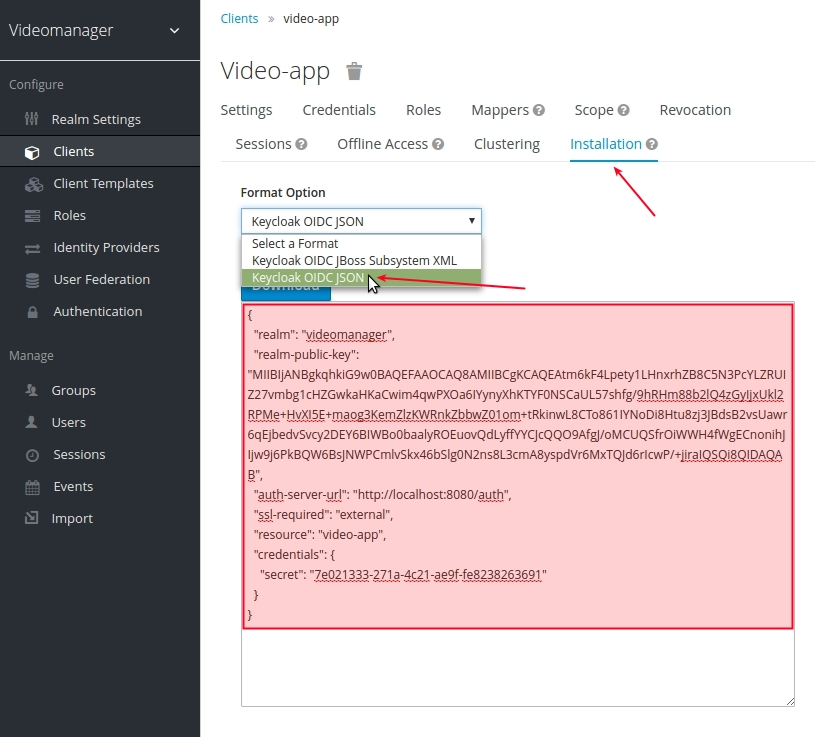 Капіюем наладкі з поля Download, ствараем у нашым праекце ў тэчцы
Капіюем наладкі з поля Download, ствараем у нашым праекце ў тэчцы WEB_INFфайлkeycloak.jsonі ўстаўляем у гэты файл наладкі KeyCloak: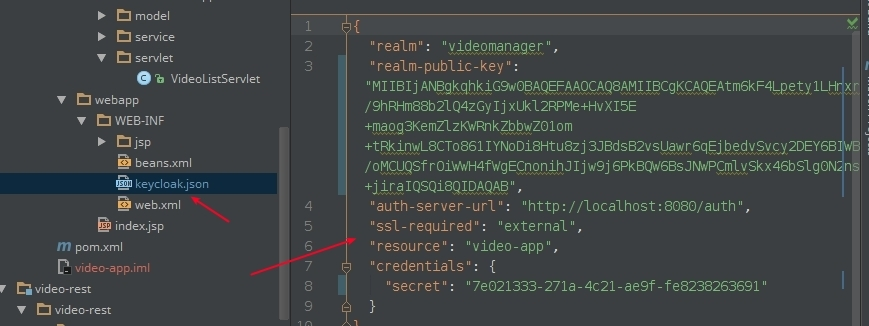
- Апошні крок, агульны для ўсіх тыпаў Java-кліентаў,– пазначыць тып аўтэнтыфікацыі ў файле
web.xml:
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-core</artifactId>
<version>${version.keycloak}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-adapter-core</artifactId>
<version>${version.keycloak}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-services</artifactId>
<version>${version.keycloak}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-jboss-adapter-core</artifactId>
<version>${version.keycloak}</version>
<scope>provided</scope>
</dependency>
<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
<!-- Declare to use KEYCLOAK authentication method -->
<login-config>
<auth-method>KEYCLOAK</auth-method>
<realm-name>videomanager</realm-name>
</login-config>
</web-app>
Вышэйзгаданае будзе аднолькава для любых Java-кліентаў. А цяпер прывядзем наладкі, спэцыфічныя для розных тыпаў кліентаў.
-
Калі гэта праграма на аснове сэрвлетаў, усё, што трэба зрабіць – гэта пазначыць абаронены сэрвлет (альбо яго асобныя мэтады) анатацыямі
@DeclareRolesі@ServletSecurity:
У гэтым выпадку пры спробе доступу да рэсурсу@WebServlet("/video-list-servlet") @DeclareRoles("video-app-user") @ServletSecurity(@HttpConstraint(rolesAllowed = {"video-app-user"})) public class VideoListServlet extends HttpServlet { }/video-list-servletпраграма вызначыць, што няма аўтэнтыфікаванай сэсіі і перанакіруе запыт да KeyCloak, адчыніцца яго старонка лагіну, пасьля ўводу лагін-інфармацыі, запыт ізноў будзе накіраваны на зыходны рэсурс/video-list-servlet. Гэтым разам будзе даступна аўтэнтыфікаваная сэсія, праграма запытае (ці атрымае гэта непасрэдна з JWT-токэну) ролю аўтэнтыфікаванага карыстальніка і, калі яго роля супадае з аб'яўленай (video-app-user), праграма задаволіць доступ да рэсурсу, інакш запыт будзе адхілены. -
Калі ж праграма зьяўляецца REST-сэрвісам, альбо зроблена на аснове JSF, патрэбна дадатковая наладка на ўзроўні
web.xml:<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"> <security-constraint> <web-resource-collection> <url-pattern>/*</url-pattern> </web-resource-collection> <auth-constraint> <role-name>video-app-user</role-name> </auth-constraint> </security-constraint> <login-config> <auth-method>KEYCLOAK</auth-method> <realm-name>videomanager</realm-name> </login-config> <security-role> <role-name>video-app-user</role-name> </security-role> </web-app>
Concurrency
Асобны модуль у дадатак да java.util.concurrent.
Spring
Учимся готовить: Spring 3 MVC + Spring Security + Hibernate на habrahabr.ru
Spring Core Tutorial на mkyong.com
Spring MVC Tutorial на mkyong.com
Spring Tutorial на tutorialspoint.com
Spring 4 Tutorial websystique.com
Spring MVC Tricks and Tutorials crunchify.com
Security
Spring Security Tutorial на mkyong.com
Boot
Патрабаваньні для вэрсіі 1.2.3.RELEASE:
- Java 7+
- Servlet 3.1+
- Spring Framework 4.1.5+
- Maven 3.2+
- Jetty 9+
Тыповая наладка ў pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>myproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<!-- Inherit defaults from Spring Boot -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<!-- Add typical dependencies for a web application -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<!-- Package as an executable jar -->
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Усталёўка CLI
Спампоўваем архіў і распакоўваем яго ў адвольную тэчку, напрыклад у /opt/spring-boot.
Ладкуем асяродак, дадаўшы ў ~/.profile:
SPRING_HOME=/opt/spring-boot
export SPRING_HOME
PATH=$PATH:$SPRING_HOME/bin
export PATH
Таксама ствараем сім-лінк :
ln -s /opt/spring-boot/shell-completion/bash/spring /etc/bash_completion.d/spring
View templates
Thymeleaf
Базы даных
Hibernate
Java Hibernate. Часть 1 — Введение
Java Hibernate. Часть 2 — Запросы
Java Hibernate. Часть 3 — Отношения
Java Hibernate. Часть 4 — Spring
Міграцыі
Зборка
Ant
Maven
Кніга «Better Builds With Maven»
Кніга «Maven: The Complete Reference»
Усталёўка
Перш за ўсё трэба каб на кампутары быў ужо ўсталяваны JDK.
$ echo $JAVA_HOME
/usr/lib/jvm/java-7-openjdk-i386
Пасьля гэтага спампоўваем дыстрыбутыў і распакоўваем яго напрыклад сюды: /usr/local/apache-maven. Пры распакоўцы будзе створана тэчка з пазнакай вэрсіі, напрыклад: apache-maven-3.0.5.
Дадаем у асяродак зьменную M2_HOME:
$ export M2_HOME=/usr/local/apache-maven/apache-maven-3.0.5
Таксама дадаем шлях да bin-тэчкі мавена ў PATH
$ export PATH=$PATH:/usr/local/apache-maven/apache-maven-3.0.5/bin
Пры неабходнасьці дадаем зьменную асяродка MAVEN_OPTS, якая вызначае ява-парамэтры, зь якімі будзе запускацца мавен:.
$ export MAVEN_OPTS="-Xms256m -Xmx512m"
Усё, мавен усталяваны і гатовы для працы. Пераканацца ў гэтым можна так:
$ mvn --version
Apache Maven 3.0.5 (r01de14724cdef164cd33c7c8c2fe155faf9602da; 2013-02-19 16:51:28+0300)
Maven home: /usr/local/apache-maven/apache-maven-3.0.5
Java version: 1.7.0_51, vendor: Oracle Corporation
Java home: /usr/lib/jvm/java-7-openjdk-i386/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "3.8.0-19-generic", arch: "i386", family: "unix"
Наладкі
У агульным выпадку пасьля ўсталёўкі мавен цалкам гатовы для працы, але бываюць выпадкі, калі патрэбныя дадатковыя наладкі. Адным з такіх выпадкаў зьяўляецца наяўнасьць проксі-сэрвэра паміж працоўным кампутарам і інтэрнэтам.
Дадатковыя наладкі мавена зьмяшчаюцца ў файле settings.xml, які ў сваю чаргу можа зьмяшчацца ў двух розных месцах:
- Тэчка мавена:
$M2_HOME/conf/settings.xml - Тэчка карыстальніка:
${user.home}/.m2/settings.xml
Першы зь іх завецца файлам глябальнай канфігурацыі, другі – канфігурацыяй карыстальніка. Калі існуюць абодва гэтыя файлы, тады выніковая канфігурацыя складаецца ў выніку іх зьліцьця, пры гэтым канфігурацыя карыстальніка мае перавагу па-над глябальнай.
Прыклад наладкі проксі-сэрвэру:
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<proxies>
<proxy>
<id>proxy</id>
<active>true</active>
<protocol>http</protocol>
<host>proxy.compony.com</host>
<port>8080</port>
</proxy>
</proxies>
</settings>
Стварэньне праекту
Стварыць новы праект можна наступным чынам (цяперашняй тэчкай павінна быць тэчка, у якой будуць зьмяшчацца вашы праекты):
$ mvn archetype:generate -DgroupId=com.company.app -DartifactId=my-app -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Гэтая каманда створыць тэчку my-app па значэньню парамэтра artifactId, а ў гэтай тэчцы наступную структуру:
my-app
|-- pom.xml
`-- src
|-- main
| `-- java
| `-- com
| `-- mycompany
| `-- app
| `-- App.java
`-- test
`-- java
`-- com
`-- mycompany
`-- app
`-- AppTest.java
Канвэнцыя па-над канфігурацыяй
Maven прытрымліваецца ідэалёгіі канвэнцыя па-над канфігурацыяй, якая азначае, што распрацоўшчыку ня трэба самому выдумляць нейкія базавыя рэчы, а Maven сам іх перадвызначае, напрыклад месцазнаходжаньне зыходнікаў, рэсурсаў, тэстаў, скампіляваных файлаў і jar-файлаў перадвызначана наступным чынам:
| Элемэнт | Перадвызначанае месцазнаходжаньне |
|---|---|
| Зыходныя файлы праекту | ${basedir}/src/main/java |
| Рэсурсы | ${basedir}/src/main/resources |
| Тэсты | ${basedir}/src/test |
| Скампіляваныя файлы | ${basedir}/target/classes |
| jar-файлы | ${basedir}/target |
POM
Дэталі праекту, залежнасьцямі і зборкай якога кіруе Maven, знаходзяцца ў файле pom.xml, які павінен знаходзіцца ў корані праекту. Яго тыпічны зьмест наступны:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<!-- вэрсія мадэлі для POM-аў Maven 2.x заўсёды 4.0.0 -->
<modelVersion>4.0.0</modelVersion>
<!-- даныя для ідэнтыфікацыі праекту, то бок набор значэньняў,
які дазваляе адназначна яго ідэнтыфікаваць -->
<groupId>com.companyname</groupId>
<artifactId>MavenExample</artifactId>
<version>0.0.1-SNAPSHOT</version>
<!-- залежнасьці ад бібліятэкаў -->
<dependencies>
<dependency>
<!-- даныя для ідэнтыфікацыі бібліятэкі -->
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<!-- на якім этапе зборкі будзе выкарыстоўвацца,
у дадзеным выпадку - выключна для запуска і кампіляцыі тэстаў -->
<scope>test</scope>
</dependency>
</dependencies>
</project>
Этапы
Запусьціць зборку праекта мавенам можна пры дапамозе кансольнай каманды mvn <ЭТАП> з месца, дзе знаходзіцца файл pom.xml (то бок знаходзячыся ў корані праекта). ЭТАП – гэта імя этапу жыцьцёвага цыкла зборкі праекта:
validate |
правярае карэктнасьць мэта-інфармацыі аб праекце |
compile |
кампіліруе зыходнікі |
test |
праганяе юніт-тэсты скампіляваных клясаў, якія атрымаліся на папярэднім этапе, выкарыстоўваючы падыходзячы тэставы фрэймворк |
package |
пакуе праект у лёгкаперамяшчаемы фармат (JAR альбо WAR) |
integration-test |
адпраўляе запакаваны праект у асяродак інтэграцыйнага тэставаньня і праганяе інтэграцыйныя тэсты |
verify |
правярае упакаваны праект на карэктнасьць і задавальненьне крытэрам якасьці |
install |
зьмяшчае пакет у лякальны рэпазыторый мавена, адкуль ён будзе даступны іншым праектам у якасьці залежнасьці |
deploy |
зьмяшчае пакет на сэрвэр для рэальнай працы |
Пры гэтым этапы асноўнага жыцьцёвага цыкла зборкі зьяўляюцца пасьлядоўнымі, і калі напрыклад запусьціць каманду mvn package, то будуць пасьлядоўна выкананы этапы validate, compile, test і напрыканцы сам package.
Акрамя гэтага у мавене ёсьць самастойныя этапы, якія існуюць па-за межамі звычайнага жыцьцёвага цыкла мавена і іх выкананьне не прыводзіць да аўтаматычнага выкананьня іншых этапаў, гэта:
clean |
выдаляе вытворныя артэфакты, якія былі створаныя мавенам раней |
site |
стварае дакумэнтацыю для праекта |
Профілі зборкі
Рэпазыторыі
Рэпазыторый мавена – гэта пляцоўка, дзе захоўваюцца джаркі праектаў, залежнасьці, плагіны і іншыя артэфакты, якія патрэбныя мавену для зборкі. Рэпазыторыі бываюць:
- лякальны – гэта тэчка на лякальным кампутары, па змоўчваньні
$HOME/.m2/repository, але можа быць перавызначана ўsettings.xml:
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<localRepository>/my/special/path/to/repo</localRepository>
</settings>
pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.companyname.projectgroup</groupId>
<artifactId>project</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>com.companyname.common-lib</groupId>
<artifactId>common-lib</artifactId>
<version>1.0.0</version>
</dependency>
<dependencies>
<repositories>
<repository>
<id>companyname.lib1</id>
<url>http://download.companyname.org/maven2/lib1</url>
</repository>
<repository>
<id>companyname.lib2</id>
<url>http://download.companyname.org/maven2/lib2</url>
</repository>
</repositories>
</project>
Калі мавену ў працэсе зборкі спатрэбіўся нейкі артэфакт, ён:
- спачатку пашукае яго ў лякальным рэпазыторыі, калі ён там ёсьць, возьме яго адтуль, інакш пяройдзе на кроку 2;
- пашукае яго ў цэнтральным рэпазыторыі (патрэбны доступ у інтэрнэт), калі ён там ёсьць, загрузіць яго ў лякальны рэпазыторый і возьме адтуль, інакш пяройдзе да кроку 3;
- калі пазначаная крыніца адлеглага рэпазыторыю, пашукае там, калі артэфакт там ёсьць, загрузіць яго ў лякальны рэпазыторый і возьме адтуль, інакш, калі патрэбнага артэфакту няма і ў адлеглым рэпазыторыі, альбо калі адлеглыя рэпазыторыі ўвогуле не пазначаныя, тады мавен спыніць працу з пазнакай памылкі.
Рэдка, але бываюць сытуацыі, калі пэўнага артэфакту няма ні ў якім з вядомых рэпазыторыяў, але ён даступны для загрузкі. У гэтым выпадку можна яго загрузіць на лякальны кампутар і дадаць у лякальны рэпазыторый наступнай камандай:
mvn install:install-file -Dfile= -DgroupId= -DartifactId= -Dversion= -Dpackaging=
Напрыклад, jdbc-драйвэр для работы з СКБД Oracle вэрсіі 10.2.0.1, можна зарэгістраваць наступнай камандай:
mvn install:install-file \
-Dfile=ojdbc14.jar \
-DgroupId=com.oracle \
-DartifactId=oracle \
-Dversion=10.2.0.1 \
-Dpackaging=jar \
-DgeneratePom=true
Плагіны
Па сутнасьці сваёй мавен – гэта фрэймворк выкананьня плагінаў. І каб зьмяніць нешта ў працэсе зборкі, якую ён робіць, усё што трэба зрабіць – гэта дадаць нейкі плагін, альбо наладзіць ужо існуючы. Напрыклад, каб наладзіць ява-кампілятар такім чынам, каб былі дазволеныя зыходнікі вэсріі 5.0, трэба зрабіць наступнае:
...
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5.1</version>
<configuration>
<source>1.5</source>
<target>1.5</target>
</configuration>
</plugin>
</plugins>
</build>
...
Кожны плагін мае мэты (goals) – гэта пэўныя атамарныя апэрацыі, і ўсё, што робіць мавен (у межах этапаў зборкі), ён робіць выконваючы пэўныя мэты розных плагінаў. Калі нейкая мэта плагіну не злучана ні зь якім этапам зборкі, яе можна выканаць непасрэдна праз плагін, а не праз этап зборкі:
$ mvn :
Jetty
Каб Jetty правяраў зьмяненьні ў праграме і аўтаматычна падгружаў іх, трэба зьмяніць змоўчнае значэньне парамэтру scanIntervalSeconds з 0 напрыклад на 1:
...
<build>
<plugins>
<plugin>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-maven-plugin</artifactId>
<version>9.2.3.v20140905</version>
<configuration>
<scanIntervalSeconds>1</scanIntervalSeconds>
</configuration>
</plugin>
</plugins>
</build>
...
Для таго, каб аўтаматычная падгрузка працавала як чакаецца, Jetty абавязкова павінен запускацца праз каманду mvn jetty:run (ні ў якім разе не mvn jetty:run-exploded; апошняя будзе прыводзіць да таго, што праграма будзе стартаваць з сабранага war-файла, і адпаведна будзе губляцца ўвесь сэнс хуткага фідбэку на зьмяненьні).
Залежнасьці
У сэкцыі dependencies файла pom.xml пералічваюцца ўсе зьнешнія залежнасьці, якія патрэбныя для таго, каб праект змог быць сабраным:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.mycompany.app</groupId>
<artifactId>my-app</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>Maven Quick Start Archetype</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
<scope>compile</scope>
</dependency>
</dependencies>
</project>
Пры гэтым у элемэнце scope пазначаецца вобласьць (scope), для якой гэтая залежнасьць мае дачыненьне, а таксама ўплывае на classpath, які ўжываецца для розных задач мавена. Магчымыя вобласьці:
- compile – гэта змоўчная вобласьць, яна ўжываецца ў тым ліку тады, калі яўна не была пазначаная. Залежнасьці пазначаныя такім чынам, даступныя ўва ўсіх classpath праекту, і больш таго, даступныя ў залежных праектах.
- provided – падобна да compile, але чакаецца, што JDK, альбо кантэйнэр самі прадставяць залежнасьці ў runtime. Напрыклад, гэта тычыцца Servlet API, які павінен прадставіць вэб-кантэйнэр.
- runtime – пазначае, што залежнасьць патрэбная не для кампіляцыі, але для выкананьня праекту. Будзе даданая ў тэставы і runtime classpath.
- test – пазначае, што залежнасьць не патрэбная для зборкі і працы праграмы, але толькі для кампіляцыі і выкананьня тэстаў.
- system – падобна да provided, але адрозьніваецца тым, што шлях да jar-файлу залежнасьці павінен быць яўна пазначаны.
- import (maven 2.0.9+) – ужываецца толькі для залежнасьцяў з тыпам pom у сэкцыі
<dependencyManagement>
Common Annotations API
<!-- 'provided' scope in case of JBoss WildFly as the API is included there -->
<dependency>
<groupId>org.jboss.spec.javax.annotation</groupId>
<artifactId>jboss-annotations-api_1.2_spec</artifactId>
<scope>provided</scope>
</dependency>
Web
<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
</web-app>
JavaEE CDI API
<!-- 'provided' scope in case of JBoss WildFly as the API is included there -->
<dependency>
<groupId>javax.enterprise</groupId>
<artifactId>cdi-api</artifactId>
<scope>provided</scope>
</dependency>
JavaServer Faces
<!-- 'provided' scope in case of JBoss WildFly as the API is included there -->
<dependency>
<groupId>org.jboss.spec.javax.faces</groupId>
<artifactId>jboss-jsf-api_2.2_spec</artifactId>
<scope>provided</scope>
</dependency>
Альбо больш vendor independent:
<dependency>
<groupId>javax.faces</groupId>
<artifactId>javax.faces-api</artifactId>
<version>2.2</version>
</dependency>
EJB
<!-- 'provided' scope in case of JBoss WildFly as the API is included there -->
<dependency>
<groupId>org.jboss.spec.javax.ejb</groupId>
<artifactId>jboss-ejb-api_3.2_spec</artifactId>
<scope>provided</scope>
</dependency>
JPA API
<!-- 'provided' scope in case of JBoss WildFly as the API is included there -->
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.1-api</artifactId>
<scope>provided</scope>
</dependency>
<!-- Annotation processor to generate the JPA 2.0 metamodel classes for
typesafe criteria queries -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-jpamodelgen</artifactId>
<scope>provided</scope>
</dependency>
<!-- Annotation processor that raising compilation errors whenever constraint
annotations are incorrectly used. -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator-annotation-processor</artifactId>
<scope>provided</scope>
</dependency>
Bean Validation
<!-- 'provided' scope in case of JBoss WildFly as the API is included there -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<scope>provided</scope>
<exclusions> <!-- Гэта патрэбна, альбо толькі для гэтага пэўнага выпадку? -->
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
JAX-RS API
<!-- 'provided' scope in case of JBoss WildFly as the API is included there -->
<dependency>
<groupId>org.jboss.resteasy</groupId>
<artifactId>jaxrs-api</artifactId>
<scope>provided</scope>
</dependency>
Лагіраваньне
<!-- 'provided' scope in case of JBoss WildFly as the API is included there -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.7</version>
<scope>provided</scope>
</dependency>
Testing
<!-- Needed for running tests (you may also use TestNG) -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<!-- Optional, but highly recommended -->
<!-- Arquillian allows you to test enterprise code such as EJBs and Transactional(JTA)
JPA from JUnit/TestNG -->
<dependency>
<groupId>org.jboss.arquillian.junit</groupId>
<artifactId>arquillian-junit-container</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jboss.arquillian.protocol</groupId>
<artifactId>arquillian-protocol-servlet</artifactId>
<scope>test</scope>
</dependency>
Gradle
Лагіраваньне
Трэба дадаць залежнасьці ў pom.xml:
...
<dependencies>
...
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.10</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.10</version>
</dependency>
...
</dependencies>
...
Дадаць наладкі Log4J у файл log4j.properties па шляху src/main/resources:
#--- comment/uncomment needed lines to use for loging -----------#
log4j.rootCategory=DEBUG, file
#------------------------------------------------------------------#
##### Appenders area #####
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.file.File=logs/app.log
log4j.appender.file.MaxFileSize=2MB
log4j.appender.file.MaxBackupIndex=5
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%5p[%d{mm:ss}]%M(%F:%L) %m%n
Тэставаньне
Аўтаматызацыя
Gauge
Getting Started with Java and IntelliJ IDEA
Cucumber
Unit-тэставаньне
The JMockit Testing Toolkit Tutorial
surefire – maven-убудаваньне для праверкі ступені пакрыцьця тэстамі.
Функцыянальнае тэставаньне
Интеграционное тестирование в Java EE
Java EE integration testing with Arquillian using Chameleon, Shrinkwrap, Drone/Graphene
UI-тэставаньне
Мікрасэрвісы
Deploying Java EE Microservices on OpenShift
Building Microservices with WildFly Swarm and Netflix OSS on OpenShift
Examples of how to write applications using WildFly Swarm
async-io: Atmosphere framework
akka.io: Build powerful concurrent and distributed applications more easily
Microservice Service Discovery with Consul
Consul Service Discovery and Health For Microservices Architecture Tutorial
Карысныя бібліятэкі
Guava: Google Core Libraries for Java
PrettyTime: intuitive Java date and timestamp formatting
HowTo's
Аналізатары кода
SonarQube
Змоўчны адміністратар: admin/admin.
Старт сэрвэра: sudo bash /opt/sonarqube-5.0.1/bin/linux-x86-32/sonar.sh start
Servers
Jetty
WildFly
Наладка SSL
how to configure ssl in wildfly 8.2.0 server?
Configuring SSL in Wildfly 8/9/10
Усталёўка драйвэра PostgreSQL
- спампоўваем адпаведную вэрсію драйвэру з https://jdbc.postgresql.org/download.html у тэчку
/tmp -
Запускаем кансоль WildFly:
і ў кансолі злучаемся з сэрвэрам:bin/jboss-cli.shYou are disconnected at the moment. Type 'connect' to connect to the server or 'help' for the list of supported commands. [disconnected /] connect [standalone@localhost:9990 /] -
Наступным крокам запускаем каманду ў кансолі:
module add --name=org.postgres --resources=/tmp/postgresql-9.4-1202.jdbc42.jar --dependencies=javax.api,javax.transaction.api,javax.servlet.api -
А потым такую:
/subsystem=datasources/jdbc-driver=postgres:add(driver-name="postgres",driver-module-name="org.postgres",driver-class-name=org.postgresql.Driver)
Цяпер у файле канфігурацыі WildFly (standalone.xml) можна дадаваць datasource да БД PostgreSQL:
<subsystem xmlns="urn:jboss:domain:datasources:4.0">
<datasources>
<datasource jta="true" jndi-name="java:jboss/datasources/PostgresDS"
pool-name="PostgresDS" enabled="true" use-java-context="true" use-ccm="true">
<connection-url>jdbc:postgresql://localhost:5432/example</connection-url>
<driver>postgres</driver>
<security>
<user-name>user</user-name>
<password>password</password>
</security>
</datasource>
...
<drivers>
...
<driver name="postgres" module="org.postgres">
<driver-class>org.postgresql.Driver</driver-class>
</driver>
</drivers>
</datasources>
</subsystem>
Воблачны хостынг
Heroku
Learn More about Heroku for Java
Deploying Tomcat-based Java Web Applications with Webapp Runner